Redis数据类型之有序集合类型Sorted Set(Zset)
本文最后更新于:2025年4月13日
想学习更多Redis相关知识,请点击右侧链接查看Redis学习笔记:点我查看
一、Redis有序集合类型介绍
Redis有序集合(Sorted Set,也称作Zset)由多个带有分数(score)的成员(member)组成。
和无序集合不同是,有序集合种的成员可以根据自己的分数按照特定规则排序。如果在有序集合中多个成员的分数相同,那么成员会按照字典序排列。
字典序(Lexicographical Order)是一种常用排序方式,类似于现实生活中英文字典的单词排序。在这个顺序中,字符串或其他序列按照字符或元素逐个比较排列。
规则:
- 逐个字符比较:从当前字符串(序列)第一个字符开始,按照ASCII或Unicode值进行比较,较小的字符排在前面;
- 比较长度:如果前面的字符相同,比较下一个字符,直到某一个字符不同或者达到当前字符串(序列)末尾。如果一个字符串(序列)是另一个字符串(序列)的前缀,那么较短的序列排在前面;
案例:
- 字符串apple和orange比较时,首字母
a比o小,因此apple排在orange前面;- 字符串iCode504与iCode504abc比较时,由于iCode504比iCode504abc短,并且iCode504是iCode504abc的前缀,因此iCode504排在iCode504abc前面;
字典序通常用于字符串排列,生成组合、排列等场景。
有序集合融合了无序集合(Set)和哈希(Hash)类型的特性:
- 有序集合中的每一个成员都是独一无二的(无序集合的特点);
- 一个成员对应一个分数(类似Hash类型种field-value)
下图展示了有序集合的存储结构并对其特点做更详细的说明:

有序集合主要体现在如下应用场景:
1. 微博热搜展示前50条词条:一个热搜词条对应Zset的成员,热度值对应当前成员的分数值:

2. 查看当前商家热销榜:商品名称作为当前Zset的成员,销量作为当前成员的分数值:

二、Redis有序集合常用类型
2.1 添加操作
使用ZADD命令,完整命令如下:
1 | |
方括号中的内容是命令选项(按照实际情况选择)。以下是关于ZADD操作的详细说明:
1. 向有序集合中添加一个或多个成员:
1 | |
默认返回的是成功向有序集合中添加的成员个数

2. 如果当前集合某个成员不存在,则执行添加操作,否则不执行添加操作:
1 | |

3. 如果当前集合中存在某个成员,则执行分数修改操作,不会新增成员:
1 | |

4. 如果新分数比当前集合中成员对应分数小,执行更新操作,否则不执行操作
1 | |

5. 如果新分数比当前集合中成员对应分数大,执行更新操作,否则不执行操作
1 | |

注意:ZADD命令中GT、LT和NX选项具有互斥性。在使用ZADD命令时,你只能使用三个中的一个。
6. 将指定的分数与成员的当前分数相加。如果成员不存在,则相当于添加成员,并将初始分数设置为给定分数。INCR 选项只能与单个 score 和 member 配合使用。
1 | |

7. 返回受影响的成员数量:
1 | |
其中CH是changed的缩写,这里说的受影响包括以下两种情况:
- 向Zset中新增成员;
- 在Zset中已经存在的成员但是分数被更新;

2.2 获取操作
1. 获取集合中成员数量:
1 | |

2. 获取成员对应的分数:
1 | |

3. 获取当前成员在当前有序集合中的索引值:
1 | |

4. (逆序)获取当前成员在当前有序集合中的索引值:
1 | |
这里说的逆序指的是将当前有序集合整体反转过来,尾部成员变为头部成员,即尾部成员对应的索引值为0:

2.3 范围获取
1. 默认按照分数从小到大排序,返回索引从start到stop之间所有的元素:
1 | |
以下是命令中各个参数的相关说明(假设当前有序集合长度是 zset.length):
key:当前有序集合的键名start:获取有序集合的开始位置,默认范围:$[0,zset.length)$或$[-zset.length, -1]$stop:获取有序集合的结束位置,默认范围:$[0,zset.length)$或$[-zset.length, -1]$

WITHSCORES:排序后显示每一个成员和对应的分数。

BYSCORE:指定此选项,将按照分数范围返回元素,此时start和stop会被解释为分数值,而不是原来的索引值。start和stop默认是闭区间,如果某一个需要开区间,只需要在前面加上一个小括号即可,例如:(startBYLEX:指定此选项,将按照字典序返回元素,此时start和stop将被解释为元素的字典顺序范围(不支持使用WITHSCORES)。


REV:反转当前的排序。

LIMIT:类似MySQL中的LIMIT关键字,其中offset是偏移量,范围在$[0, zset.length-1)$,count是显示数据个数,获取排序后的结果集中$[offset, offset + count)$区间内的数据。在使用LIMIT时,需要配合BYSCORE或BYLEX使用:

2. (Redis 6.2.0以后过时)反转当前有序集合的排序:
1 | |

3. (Redis 6.2.0以后过时)获取指定分数范围的成员:
1 | |

4. 获取指定分数范围的元素个数:
1 | |

2.4 其他操作
1. 删除一个或多个成员:
1 | |
默认返回成功删除成员个数:

2. 增加某个元素的分数:
1 | |

3. 从键名列表中的第一个非空排序集中弹出一个或多个元素,弹出的元素是成员分数对
1 | |
2.5 多集合运算
和无序集合一样,有序集合也可以多集合运算,接下来我们通过一个案例来讲解相关的命令和对应的参数。
已知通过ZADD命令添加了两个有序集合myzset1和myzset,添加的元素如下图所示:

当前两个有序集合中成员和对应的分数如下图所示:

以下是多个集合计算相关的命令:
1. (Redis 6.2.0新增)获取两个集合的并集:
1 | |
以下是对该命令中相关参数的说明:
numkeys:表示有多少个有序集合参与并集运算;key [key ...]:指定多个有序集合的键名;

WITHSCORES:返回结果中每一个成员包含分数;

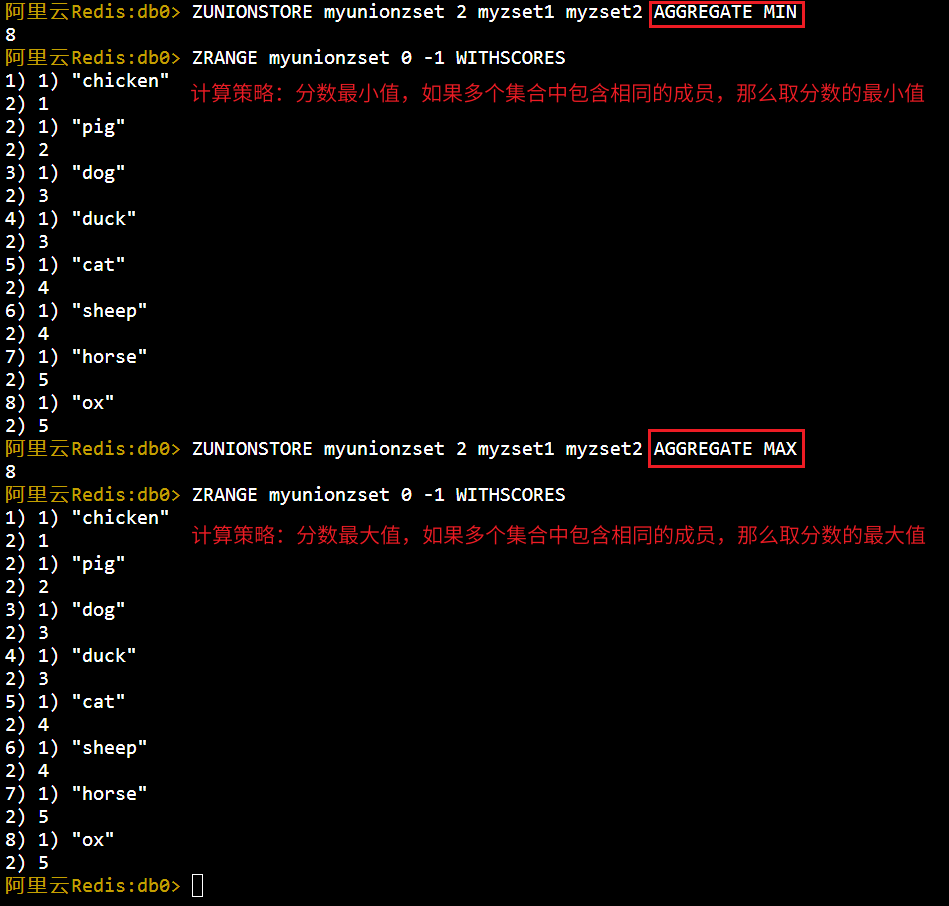
AGGREGATE <SUM | MIN | MAX>:指定并集运算中,如果相同的成员存在于多个集合中,如何计算其分数,可以下面任意一个选项:SUM(默认策略):分数相加;MIN:取最小的分数;MAX:取最大的分数。


WEIGHTS weight [weight ...]:为有序集合指定一个乘积因子,将集合中的每个元素的分数乘以该因子;

2. 获取有序集合的并集并存储:
1 | |
和前面的并集计算不同的是:使用ZUNIONSTORE计算出的结果需要指定一个key来保存。
该命令中除了 destination是要保存的key的名称,其他使用到的参数和并集命令中的参数用法相同,这里不再赘述。



3. (Redis 6.2.0新增)获取两个集合的并集:
1 | |
命令中使用到的参数和并集命令中的参数用法相同,这里不再赘述。





4. 获取有序集合的交集并存储:
1 | |
命令中使用到的参数和并集命令中的参数用法相同,这里不再赘述。
其中 destination是存储交集计算后的键名。如果 destination里面有数据,那么就会执行覆盖操作。



5. (Redis 7.0.0新增)获取有序集合的交集后成员的数量:
1 | |
其中LIMIT是限定成员返回的数量:

6. (6.2.0新增)获取有序集合的差集:
1 | |

7. 获取有序集合的差集并存储:
1 | |
其中 destination是存储差集计算后的键名。如果 destination里面有数据,那么就会执行覆盖操作。
该命令默认返回的是差集计算后的元素个数:
